
Selecting a deep learning object detection model for an embedded TensorFlow Lite application is an exercise in tradeoffs. There are variety of lightweight models to choose from that each have their own speed and accuracy characteristics. Larger models like EfficientDet have high accuracy, but their increased size results in slow inference speeds. Smaller models like SSD-MobileNet have fast inference speeds but lower accuracy. How do you decide which TensorFlow Lite model to use for your application?
To help you choose a model, this article provides empirical data showing the speed and accuracy of several TensorFlow Lite models when trained with a custom dataset and ran on a Raspberry Pi 4. You can explore these results and use them to select the model that has the right performance level for your use case.
Models and Metrics Measured
This article focuses on models available through TensorFlow, including models from the TF2 model zoo, the TF1 model zoo, and TFLite Model Maker. I selected several models from these sources and tested their performance. I also tested the models’ performance when quantized (if the architecture supports quantization with TFLite). The following models were tested:
- SSD-MobileNet-v2 (floating point and quantized)
- SSD-MobileNet-v2-FPNLite-320x320 (floating point and quantized)
- EfficientDet-d0
- SSD-MobileNet-v1 (quantized)
- EfficientDet-Lite-D0
Each model has its speed and accuracy metrics measured in the following ways:
- Inference speed per TensorFlow benchmark tool
- FPS achieved when running in an OpenCV webcam pipeline
- FPS achieved when running with Edge TPU accelerator (if applicable)
- Accuracy per COCO metric (mAP @ 0.5:0.95)
- Total number of objects correctly labeled in 75 test images
Methodology
Each model is trained off an image dataset of 750 pictures of US coins. This is a relatively small dataset, but it’s representative of the amount of images a typical developer might have when setting out to make a prototype.
Training is performed using my open-source Colab notebook for training TensorFlow Lite models. (The EfficientDet-Lite-D0 model is trained using TFLite Model Maker.) The models are trained for about 40,000 steps, or until the point when their training loss stops decreasing. The models are exported in floating point FP32 format and quantized INT8 format (if quantization is supported).
Once the models are exported, their speed and accuracy is evaluated using the methods described below.
Measuring Model Speed
A model’s inference speed is the amount of time it takes to process a set of inputs through neural network and generate outputs. When an object detection model runs inferencing on an image, it must propagate the input image through each layer of the network, performing layer operations and calculating values of nodes until the final output layer is reached. The more layers and nodes a model has, the longer inferencing takes.
I measured each model’s inference speed on a Raspberry Pi 4 8GB edition that had been set up with TensorFlow Lite following the instructions from my TFLite on the Raspberry Pi guide. To measure raw inference time, I used Google’s performance benchmark tool for TensorFlow Lite models (https://www.tensorflow.org/lite/performance/measurement). I used the following set of commands to download and run the benchmark tool on the Pi:
# Commands to download and run TFLite benchmark tool
cd ~/tflite1
wget -O benchmark_model https://storage.googleapis.com/tensorflow-nightly-public/prod/tensorflow/release/lite/tools/nightly/latest/linux_arm_benchmark_model_plus_flex
sudo chmod +x benchmark_model
./benchmark_model --graph=<graph_name>/detect.tflite --num_threads=4 --warmup_runs=10 --num_runs=100
The tool reports minimum, maximum, and average inference speed from 100 iterations. I recorded the average speed. Here’s an example of the tool’s output when running on the SSD-MobileNet-v2 model.
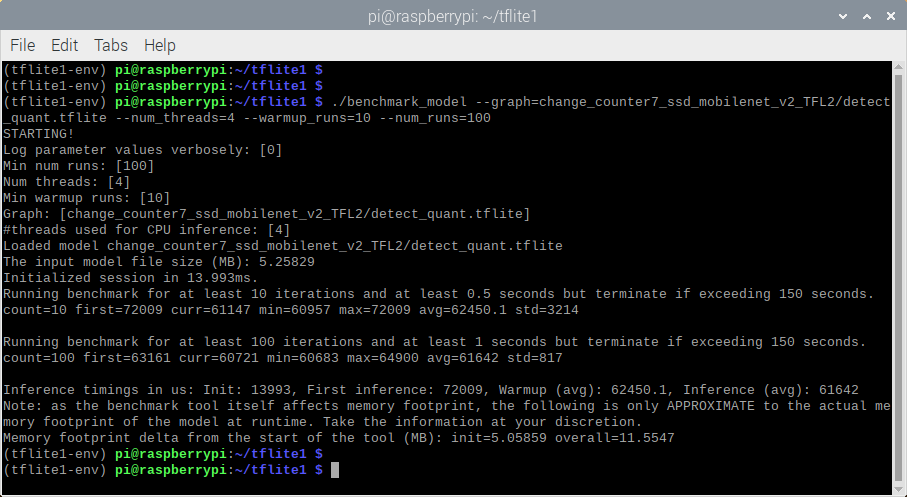
Figure 1. Example output from TensorFlow Lite's benchmark_model tool
As another method for testing speed, I ran each model with my TFLite_detection_webcam.py script to process webcam images in real-time and calculated the average frames per second (FPS) achieved after running for 200 frames. The webcam was run at 1280x720, which is a typical resolution for a computer vision application. I repeated the test with Google’s Coral USB Accelerator (on compatible models only) to determine the throughput when running on an Edge TPU.
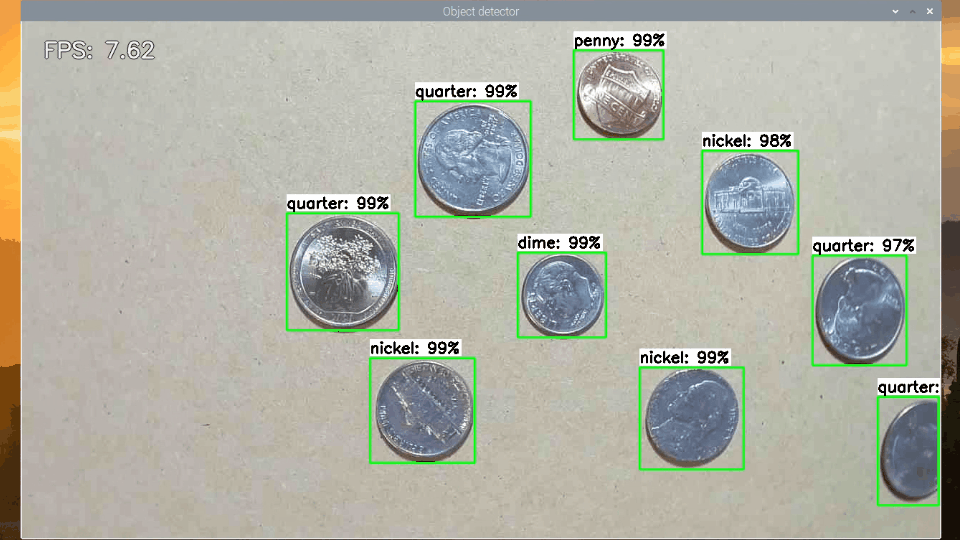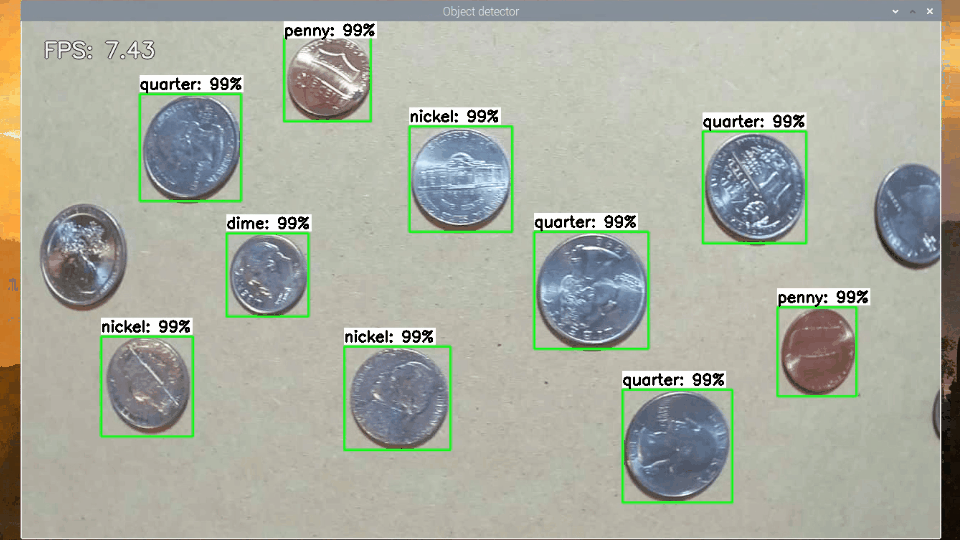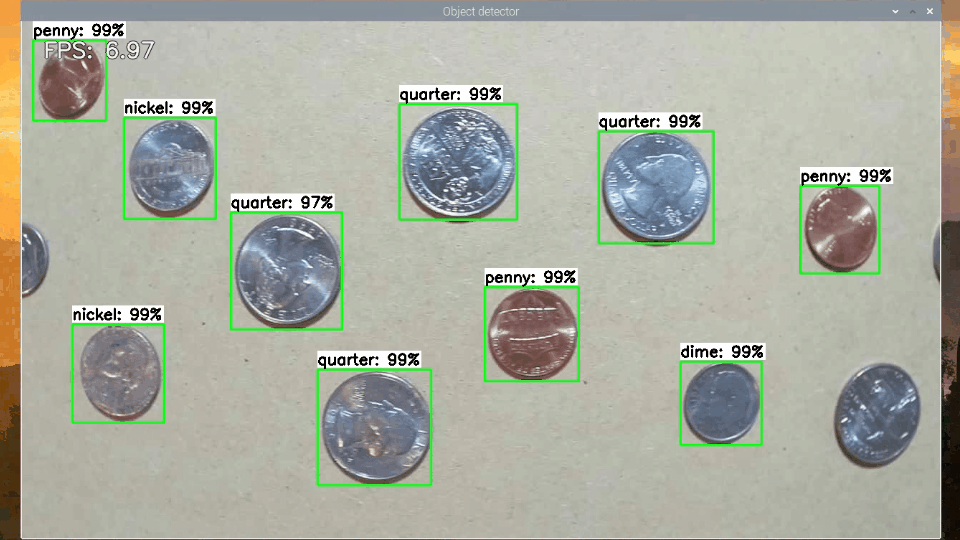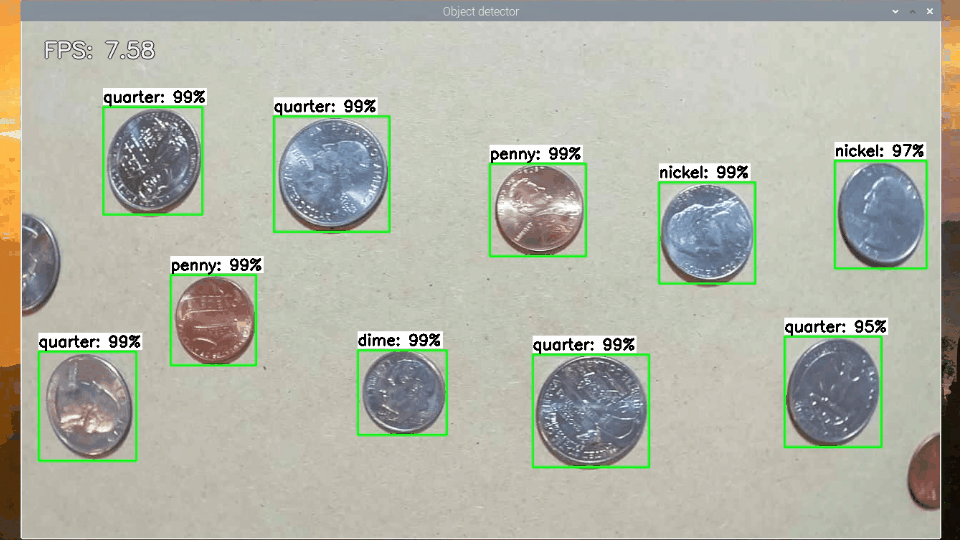
Figure 2. Measuring SSD-MobileNet-v2-FPNLite model throughput in FPS with TFLite_detection_webcam.py (running on EdgeTPU)
This isn’t a true measurement of the model’s inference speed, because the FPS is constrained by how long it takes OpenCV to grab frames from the camera and display labeled images to the screen. However, it does give a good sense of how fast the model will actually run in your application.
Measuring Model Accuracy
The common metric for measuring model accuracy is mAP, or “mean average precision”. The model runs inferencing on a set of test images, and the inference results (i.e. the predicted classes and locations of objects in the images) are compared to the ground truth data (i.e. the actual correct classes and locations of objects in the images). The mAP score is calculated off the accuracy of the predictions: the higher the mAP score, the better the model is at detecting objects in images. To learn more about mAP, read this insightful blog post from Roboflow.
I used an open-source mAP calculator from GitHub user Catchuro to calculate the accuracy of each model. I wrote a script to interface with the calculator and calculate the COCO metric for mAP @ 0.50:0.95. I calculated accuracy on a test dataset of 75 images. The screenshot below shows an example of the script in action.
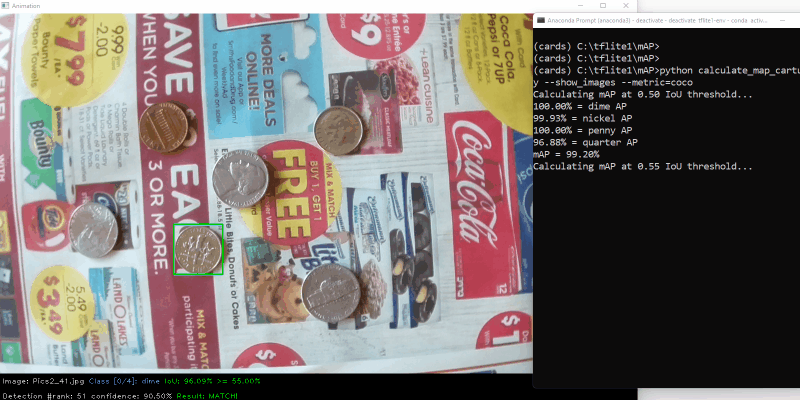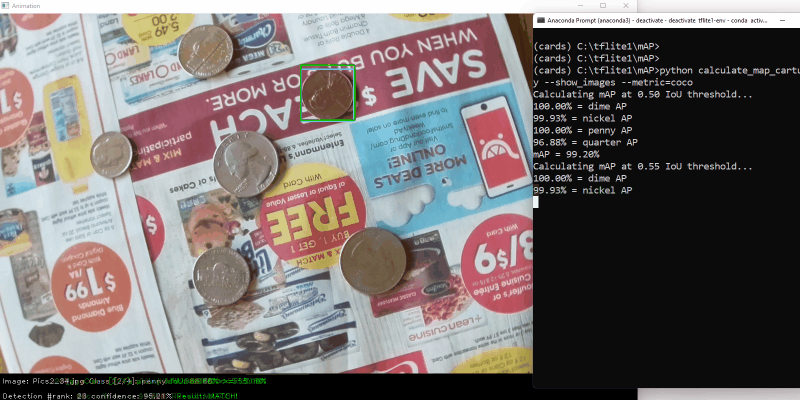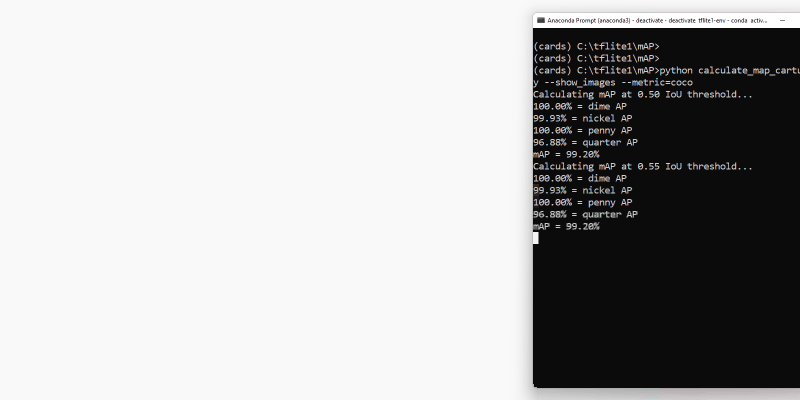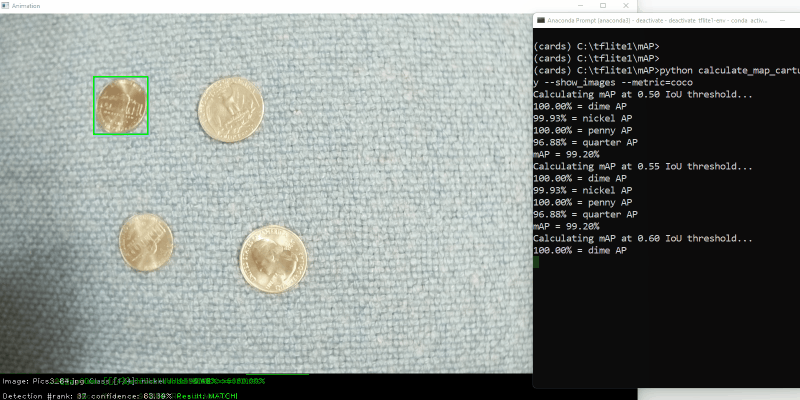
Figure 3. Calculating COCO mAP score @ IoU = 0.5:0.95
For more information on how to calculate model mAP, or if you want to try it yourself, see my article on “How to Calculate TensorFlow Lite Model mAP”. (Still a work in progress, but the link will be added when it’s ready!)
While mAP is a great metric for quantitatively comparing models, it isn’t very intuitive for helping you to understand how well a model actually performs at detecting objects in images. To give a more qualitative sense of each model’s accuracy, I also checked the total number of objects that were correctly detected (with a confidence of at least 50%) in the set of 75 images.

Figure 4. Comparing number of objects correctly labeled by EfficientDet-Lite-D0 (left) and SSD-MobileNet-v2-FPNLite (right)
Results
Alright, enough explanation, let’s see some results! In the tables below, FP32 refers to floating point models, and INT8 refers to quantized models.
Model Speed Results
Table 1 shows the inference time and application throughput of each model. For quantized models, it also shows the throughput achieved on the Edge TPU. (Edge TPUs like the Coral USB Accelerator are hard to get a hold of nowadays, so the Edge TPU results are mainly included for the sake of completeness.)
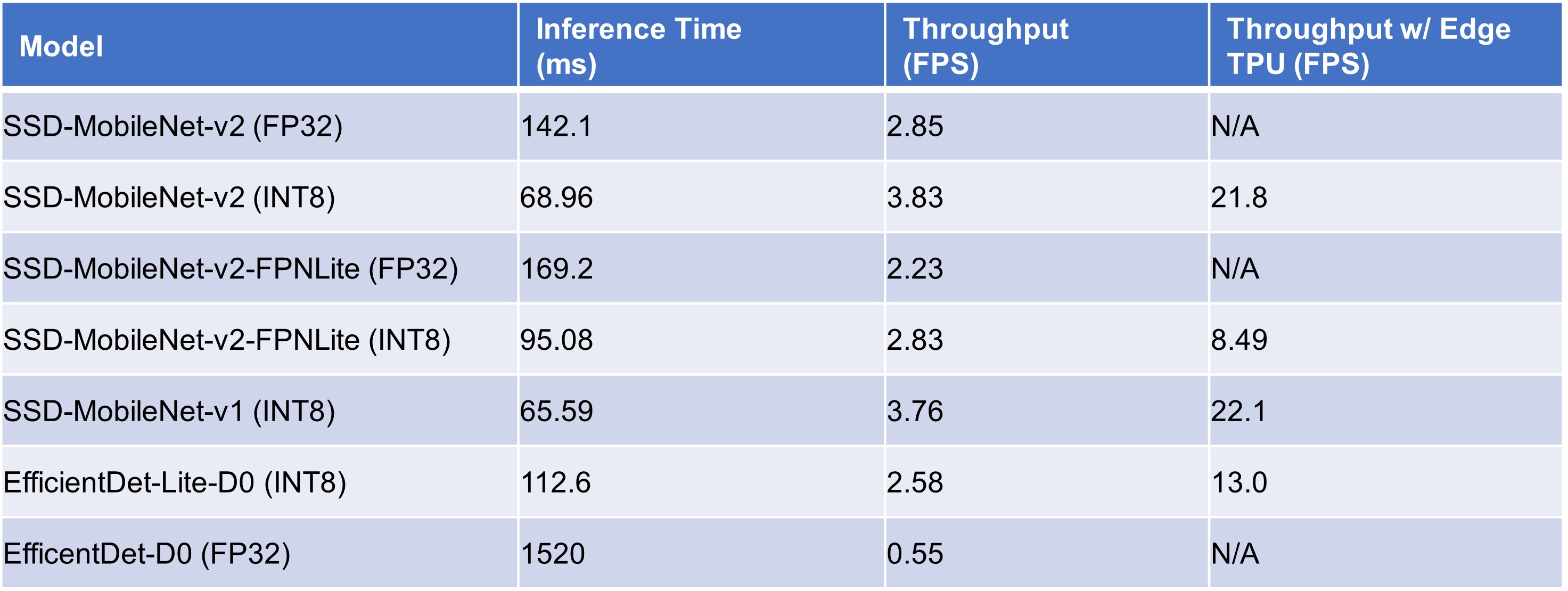
Table 1. Model inference time and overall throughput in a 1280x720 live webcam application
Figure 5 shows the speed results in graph form. Models are shown in order of fastest to slowest (from left to right).
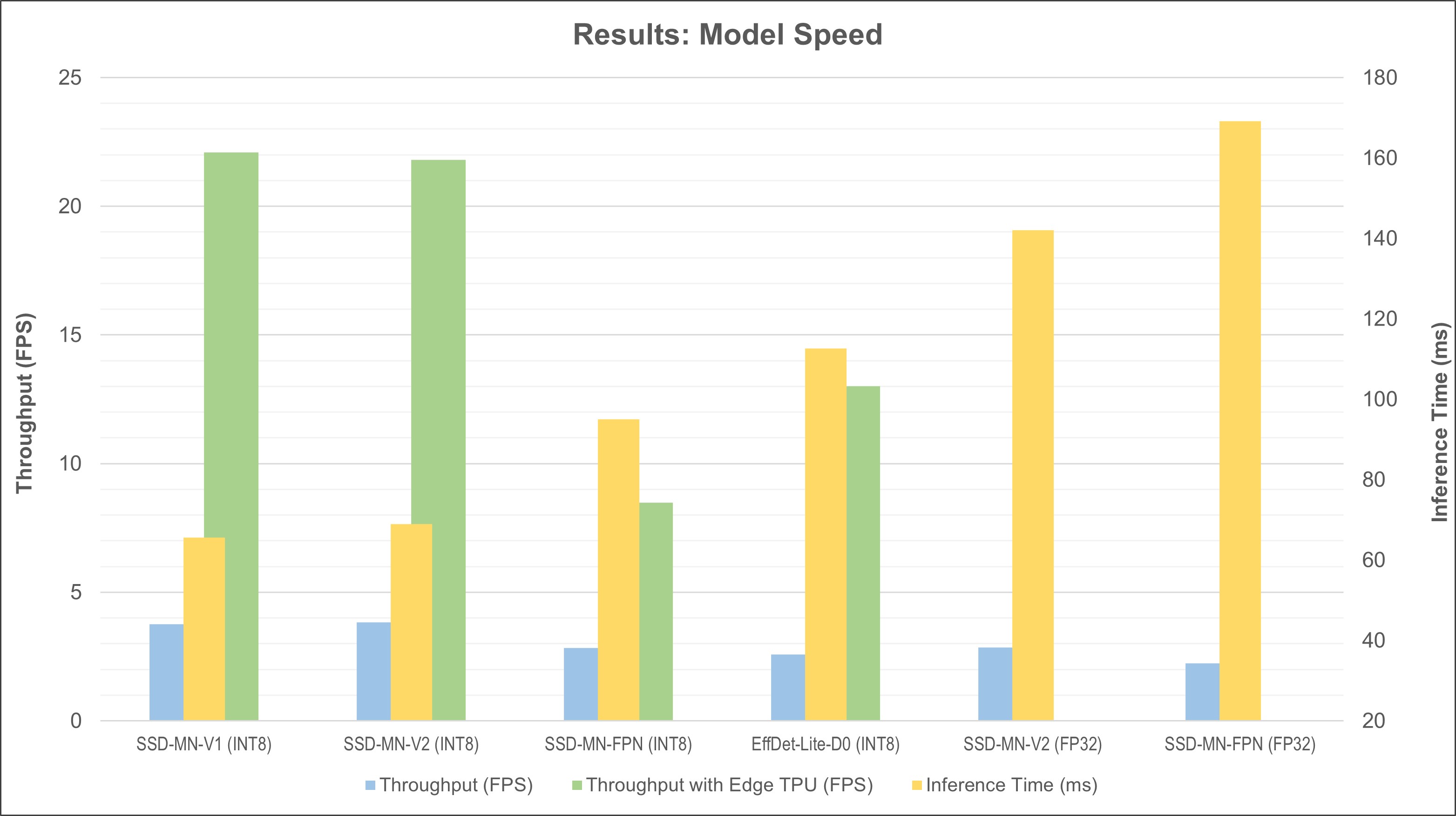
Figure 5. Model speed in inference time, throughput, and throughput with EdgeTPU.
Model Accuracy Results
Table 2 shows the COCO accuracy score (mAP @ IoU 0.5:0.95) for each model. It also shows the number of objects correctly labeled in the test dataset (out of 335 total objects). EfficientDet-D0 isn’t shown in the graph because its inference time is an order of magnitude slower than the other models.
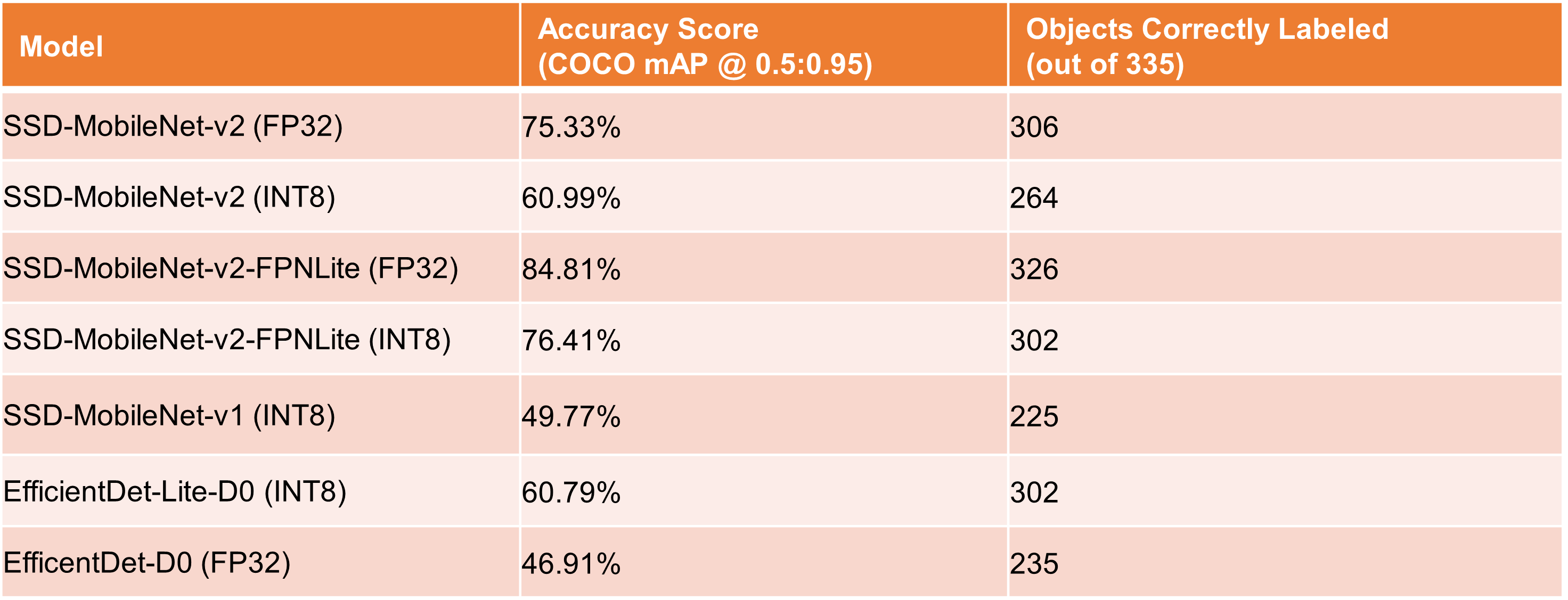
Table 2. Model accuracy score and total number of correctly labeled objects in dataset
Figure 6 shows the accuracy results in graph form. Models are shown in order from most accurate to least accurate (from left to right). EfficientDet-D0 is again not shown in the graph due to its poor performance.
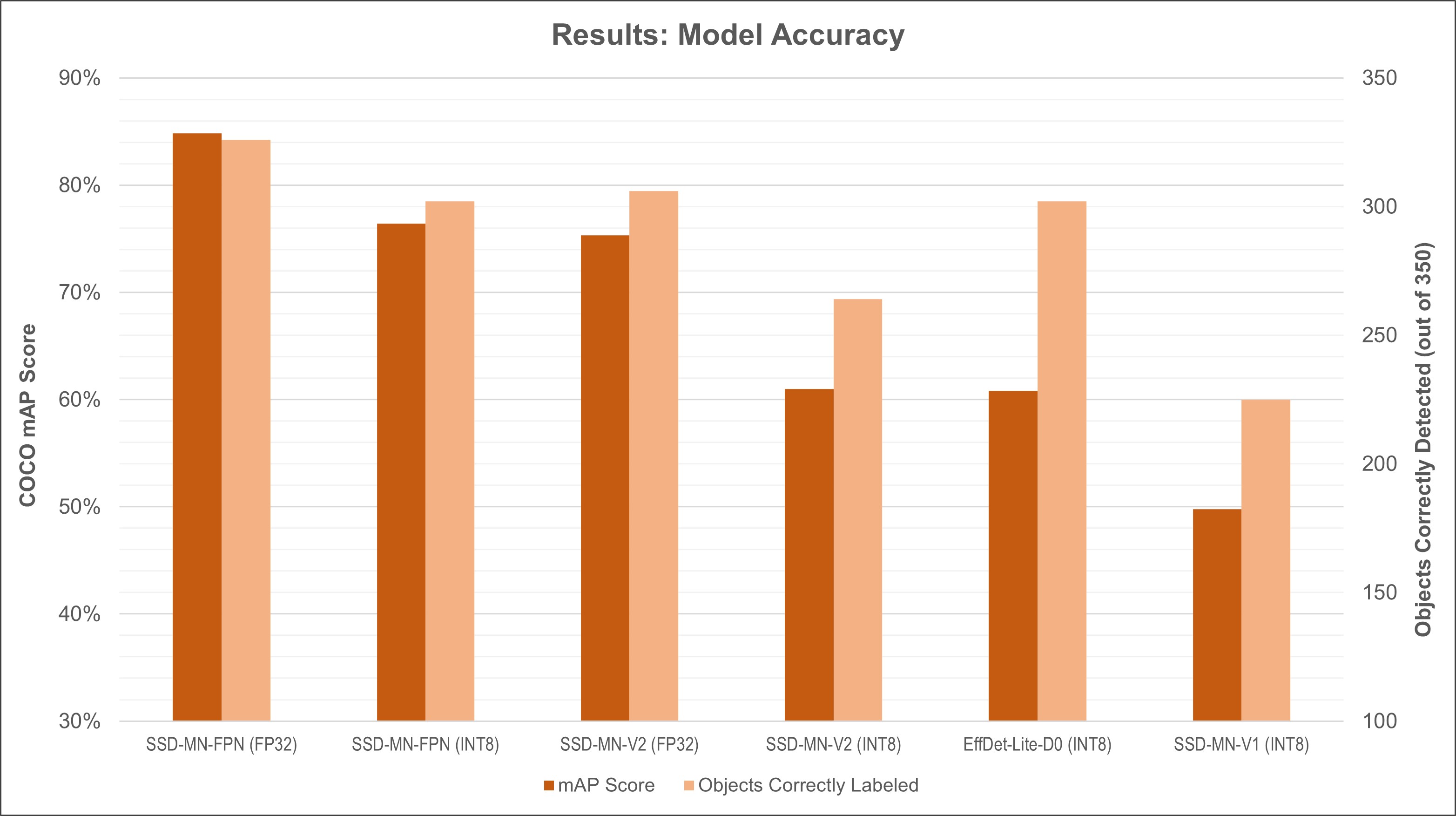
Figure 6. Model accuracy results in COCO mAP score and number of correctly labeled objects (out of 335 total objects)
Here’s a summary of each model’s performance based on the data above.
SSD-MobileNet-v2: With an inference time of 68.96 ms and a COCO mAP score of 60.99%, the quantized version of this model strikes a good balance between speed and accuracy. The floating point version can be used for a decent boost in accuracy with only a slight reduction in speed.
SSD-MobileNet-v2-FPNLite: It’s not quite as fast as regular SSD-MobileNet-v2, but it has excellent accuracy, especially considering the small size of the training dataset. It’s able to successfully detect 306 out of the 335 total objects in the test images. While the total number of objects detected is only slightly higher than EfficientDet-Lite-D0, it generally had 90% - 99% confidence in its predictions, while the EfficientDet model confidences ranged widely between 50% - 95%.
SSD-MobileNet-v1 (quantized): This model is the fastest but also the most inaccurate. Sometimes I’ve seen this model have better accuracy than quantized SSD-MobileNet-v2 when trained on certain datasets. For this dataset, however, the low accuracy is so low that it’s almost unusable. This model comes from the TensorFlow 1 model zoo and is pre-configured for quantization-aware training, so it theoretically should have better accuracy than other models when quantized. Consider trying this model if you see poor accuracy with your quantized SSD-MobileNet-v2 model.
EfficientDet-Lite-D0: Taking fifth place in accuracy and fourth place in speed, this model has middle-of-the-road performance. It may be a good alternative to try if other models don’t have high enough accuracy on your dataset. Note that it has considerably faster speed than SSD-MobileNet-v2-FPNLite on the Edge TPU because it’s been architected to be fully compatible with Edge TPU operations.
EfficientDet-D0: This model is slow and performed inaccurately on this dataset. The poor accuracy is likely due to the limited size of the coin dataset I used for training. Theoretically, this model should be able to achieve higher accuracy than any other model in this list. It should only be used in applications with higher compute power and where a larger training dataset is available.
Conclusions
Here are my top recommended models based on the results of this test.
First Place: SSD-MobileNet-FPNLite-320x320
This model has exceptional accuracy (even when trained on a small dataset) while still running fast enough to achieve near real-time performance. If you need high accuracy and your application can wait a few hundred milliseconds to respond to new inputs, this is the model for you.
Why is this model my favorite? Generally, accuracy is much more important than speed. This is especially true when creating a prototype that you want to demonstrate to stakeholders or potential investors. (For example, it’s more embarrassing when your Automated Cat Flap prototype accidentally lets in a raccoon because it was mis-identified as a cat than when it takes three seconds to let in your cat instead of two seconds.) SSD-MobileNet-FPNLite-320x320 has great accuracy with a small training dataset and still has near real-time speeds, so it’s great for proof-of-concept prototypes.
Second Place: SSD-MobileNet-v2
The SSD-MobileNet architecture is popular for a reason. This model has great speed while maintaining relatively good accuracy. If speed is the most crucial aspect of your application, or if it can get away with missing a few detections, then I recommend using this model. The low accuracy can be improved by using a larger training dataset.
Third Place: EfficientDet-Lite-D0
This model has comparable speed to SSD-MobileNet-FPNLite-320x320, but it has worse accuracy on this dataset. I recommend trying this model if you aren’t achieving good accuracy with the SSD-MobileNet models, as the different architecture may perform better on your particular dataset. Note that larger (and thus more accurate) EfficientDet-Lite models are trainable through TFLite Model Maker, but they will have much slower speeds.
Thanks for your time reading this article, and I hope the information helps you when deciding which TensorFlow Lite model to train for your application. There are many other factors and variables that affect speed and accuracy, but these results can give you a baseline comparison point for choosing a model. Again, you can train custom TFLite models for free using my TFLite training notebook on Google Colab, so go check that out if you haven’t already.
EJ Technology Consultants can help with detailed tradeoff analysis to ensure you select the right model for your vision-enabled product or application. Please visit ejtech.io or email info@ejtech.io if you’d like to learn more.